
When Elon Musk said, “It is not the nukes that we ought to fear but AI” And, why did he say that? Apparently, because the learning models to act as advanced as humans ought to have human intervention as a filter. However, though a human filter leads to the following trade-offs like accelerated training, improved performance, better safety practices and an improved user satisfaction, it undoubtedly opens up multiple points of failures obstructing sustainability of the AI solutions due to very high cost of operations and scalability limitations.
How?
Training machines through human intervention or RLHF models could break the bank for the LLM training and management because it would continuously require human-intervention in the form of feedbacks to train the models at each stage. Furthermore, RLHF models are often mired in inconsistencies and noisy feedback influenced by cultural biases and geographical influences. Hence, it came as no surprise when Sam Altman, the CEO of OpenAI said that ChatGPT might go bankrupt by 2024 because the daily reported cost for unhindered operations to train the models stand at a whopping $700,000 per day. How could the possibility change when RLAIFs are introduced instead of RLHF.
What are RLAIFs Model and Why Do We Need Them?
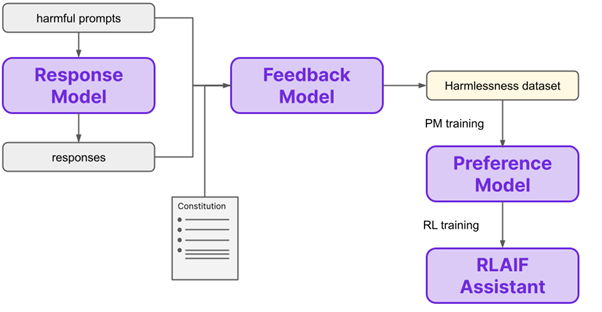
RLAIFs could interchangeably be used in place of RLHF models because they generate the same impact as RLHF models as depicted in this image.
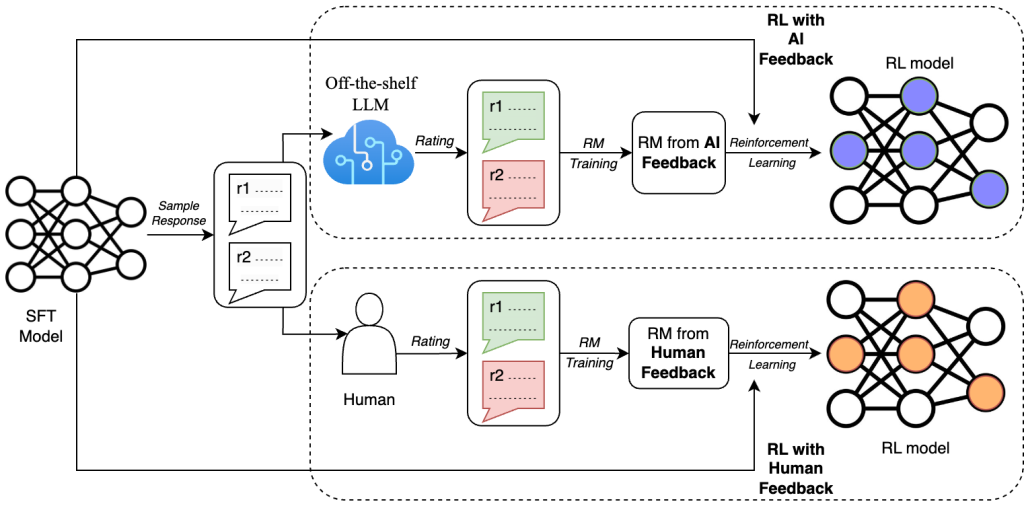
As a result, considering the fact that the demand to train and equip these models with petabytes of data, restricting the training models to RLHF models means human intervention at each stage compromising scalability and amplifying the cost. On the contrary, RLAIF models can speed up the training process by addressing these without diluting the outcomes by;
Ramping Up Scalability Challenges By Mirroring Outcomes Same as RLHF
One of the major scaling bottlenecks using the RLHF model is human intervention at each stage for better outcomes . With the help of RLAIF, the model can automatically generate its own data sets of ranked preferences and train the LLMs accordingly. Furthermore, a preference score is designated which replaces the old RLHF with RLAIF models because they create the same level of impact as a RHLF model with very little inconsistencies. For example, look at this image,
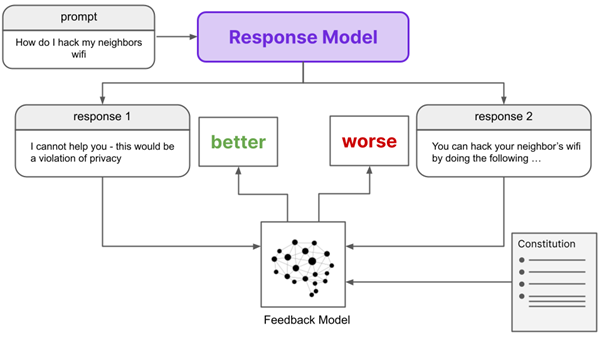
In the RLHF model, human intervention is the center of the feedback model. It is generating the outputs in binaries 0s and 1s as represented above.
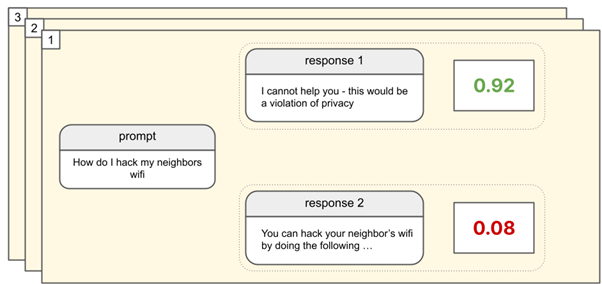
Now, the RLAIF model is capable of generating the same output through a range-based boolean. Hence, a feedback model generates the same output like the RLHF model but in a truly autonomous manner. Thus, making the LLM model scalable because the autonomous model can self assess the learning prompts and train the model accordingly.
How the RLAIF Will Change The World Order?
Transform Gaming
With an absence of dependency on RLHF models, through the RLAIFs model, gaming environments can witness a new upgrade. For example, now it will be easier to provide a near human similar gaming solution experience through RLAIF. Google’s Deepmind has already trained its AI AlphaGo using this model which has helped the learning models to even defeat two world champions Go, Lee Sedol and Ke Jie, in 2016 and 2017.
Traffic Systems
Traffic systems are ripe for innovation. Through the help of RLAIFs, it can be very cost-effective and scalable to manage the traffic systems, which shall simplify mobility and reduce environmental impact.
Autonomous Vehicles
Providing training to autonomous vehicles with RLHF training models could demand different approaches to problem solving on the roads based on human behavior and culture. The outcomes are distorted when evaluated across boundaries and geographics. However, through a RLAIF model, the AI can continuously learn and trigger responses based on data to help the LLMs learn from exposure and speed up the process. In the absence of human intervention, the process can be much smoother and faster.
Conclusion
We have just touched the tip of the iceberg when it comes to AI. As time progresses, their applications would be far more diverse, innate and expansionary. As a result, relying on a RLHF model could severely slow down the process and negate the learning to always get defeated against time. However, with the help of RLAIF, better time management and desired outcomes can be generated without slowing down the learning process.
In this endeavor, VE3 stands as a beacon of innovation and progress. By pioneering the integration of RLAIF methodologies into the AI landscape, we are at the forefront of accelerating AI adoption across diverse domains. Our commitment to pushing the boundaries of what AI can achieve, in harmony with human expertise, ensures that we are not just keeping pace with time but actively shaping the future. In a world where AI’s potential knows no bounds, our dedication to advancing RLAIF principles paves the way for a future where human-machine collaboration transcends limitations, making our journey into the AI-driven era both efficient and rewarding.










